Tout commence par un article du magazine Le Point qui publie une grande enquête sur la pollution aux particules PM 2.5 en France. Ils ont compilé des données et publient un comparatif des 35 000 communes françaises. Le lien ici : https://www.lepoint.fr/classements/qualite-air/
Habitant à Sallanches, en Haute-Savoie, et cherchant des coins d’herbe plus verte, cette étude m’a intéressée au plus grand point. En effet, en plein mois de février, la ville pue l’essence, le feu de cheminée et les épisodes de pollution s’enchainent. Mais peut-on encore trouver des endroits où l’on respire sereinement en Haute-Savoie ?
Une fois l’abonnement pris sur le site internet du Point, je m’empresse de consulter la liste des communes françaises. Cependant, malgré la qualité du listing, c’est un peu frustrant car on ne peut consulter que les 2000 premières (les moins polluées) communes françaises. Ensuite il faut uniquement utiliser le moteur de recherche. Ça manque un peu de carte, de pouvoir filtrer / trier les résultats,… Et là me vient l’idée, mais si je pouvais extraire les données pour me créer ma petite data visualisation perso ?
Vous voulez savoir comment j’ai fait pour en arriver à une « belle » carte qui met en évidence les coins les moins pollués de Haute-Savoie ? Alors suivez-moi ci-dessous, je vous explique les différentes étapes pour arriver à ce résultat. Petit indice, ça mêle mes 2 métiers : développeur web et Data Analyst.
NB : Si vous souhaitez reproduire les manipulations ci-dessous, vous devez absolument souscrire un abonnement au site Le Point pour respecter leur travail. Vous allez vous rendre compte qu’en pratique l’accès aux données est accessible à tous mais ça serait une violation des droits d’auteur. Le premier mois d’abonnement est à 1 €, donc c’est vraiment pas grand chose.
NB 2 : Il faut voir les manipulations ci-dessous comme une exploitation à grande échelle du moteur de recherche du site Le Point. Je me suis limité à la Haute-Savoie pour éviter de balancer quelques dizaines de milliers de requête sur leur site Internet. Toujours pareil, si vous souhaitez reproduire la procédure, vous devez le faire pour votre usage personnel uniquement et dans un cadre raisonnable.
Dernier point, je me suis juste lancé là dedans pour le défi technique, je n’ai même pas cherché à savoir si des cartes et études connexes existaient déjà ailleurs (et je suis sûr qu’il y en a plein), faut voir ça comme un passe temps qui m’a pris quelques heures sur un weekend (et un peu plus pour écrire cet article ensuite).
Trêve de blabla, voici le programme :
- Analyse du site Internet du Point pour comprendre comment extraire les données
- Récupération des données sur les communes françaises
- Grosse partie de data management sur les données des communes
- Récupération « industrielle » des données du site internet du Point avec Symfony
- Affichage des données sur une carte avec Tableau
1/ Comment extraire les données de pollution du site internet Le Point ?
Une fois votre abonnement pris au site internet du Point, vous avez donc accès à cette page : https://www.lepoint.fr/classements/qualite-air/ qui ressemble à ça :
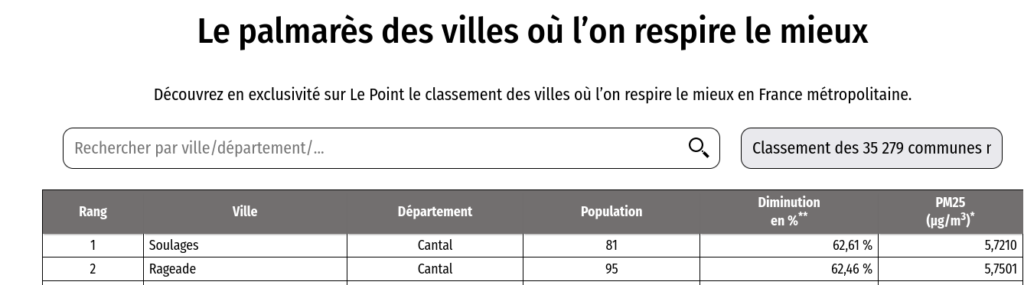
C’est très bien mais on est loin de la belle carte qu’on souhaite avoir pour mettre en valeur les résultats.
L’idée est de voir d’où viennent les données et comment peut-on les extraire à partir d’un système tierce (dans notre cas ça sera une application Symfony).
Petit point technique : j’utilise Ubuntu (Linux) et Firefox, donc ça diffère un peu pour les utilisateurs de Chrome ou autre navigateur.
On commence par afficher l’outil d’inspection de Firefox puis l’onglet « réseaux ». Ensuite on sélectionne l’option « XHR » pour n’afficher que les requêtes Ajax. En effet, on peut difficilement imaginer que les données des 35 000 communes soient chargées intégralement au chargement de la page web, ça serait un non sens. En regardant les requêtes XHR, on va regarder les requêtes faites par le code Javascript quand on saisit une ville dans le champ de recherche de la page web.
Tapez ensuite le nom d’une ville dans la barre de recherche et vous verrez en même temps plusieurs requêtes XHR être exécutées.

Vous devriez voir plusieurs requêtes vers le fichier datas.php, en gros une requête pour chaque caractère tapé dans la barre de recherche. Ci-dessus j’ai filtré les résultats pour n’afficher que les lignes contenant « datas » car il y a aussi (malheureusement) plein de requêtes parasites vers des sites de pub / tracker d’activité …
Le job est ensuite de comprendre le processus de requête / réponse pour chaque appel ajax. On va s’intéresser à 3 points :
- Quelles sont les données envoyées au moment de la requête
- Quelles sont les données de réponse à cette même requête
- Quels sont les headers envoyés pour chaque requête
Je ne rentre pas dans tous les détails ici mais on va se concentrer uniquement sur le dernier appel (celui avec le nom complet de la ville).
Le but est d’analyser ce processus de requête / réponse pour pouvoir le dupliquer dans Symfony ensuite. On affiche donc le détail de la dernière ligne (requête). Ci-dessous les en-têtes de notre requête.
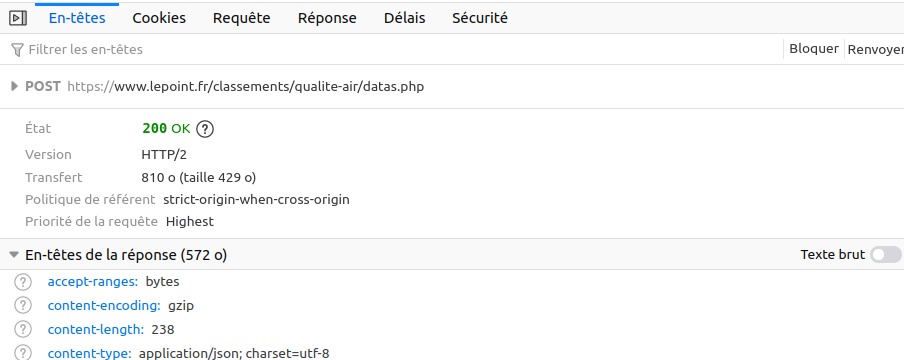
On voit qu’il s’agit d’une requête de type « POST » (et non GET comme on aurait pu le supposer). Je fais l’impasse sur l’onglet cookies mais c’était ma plus grosse interrogation sur la sécurité. Il y a une tonne de cookies qui sont envoyés avec la requête mais, a priori, ils sont tous plus ou moins liés à la pub. Sur les CORS, ça peut aussi poser un souci si on requête cette URL depuis un domaine externe (ex: toutes les requêtes vers https://www.lepoint.fr/classements/qualite-air/datas.php qui ne proviendraient pas du domaine lepoint.fr pourraient être refusées). On testera tout ça un peu plus tard.
Quelles sont les données envoyées au serveur quand on recherche, par exemple, « Sallanches » ? Voici la réponse :
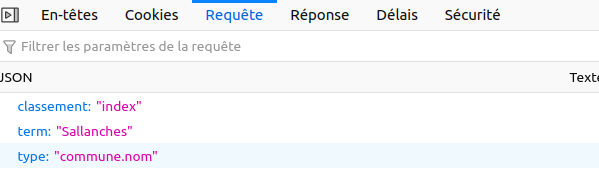
Ci-dessus le « json payload ». C’est très simple à comprendre, il suffit de changer le champ « term » par un autre nom de ville pour avoir un autre résultat.
Et quelle est la réponse du serveur suite à cette requête ?
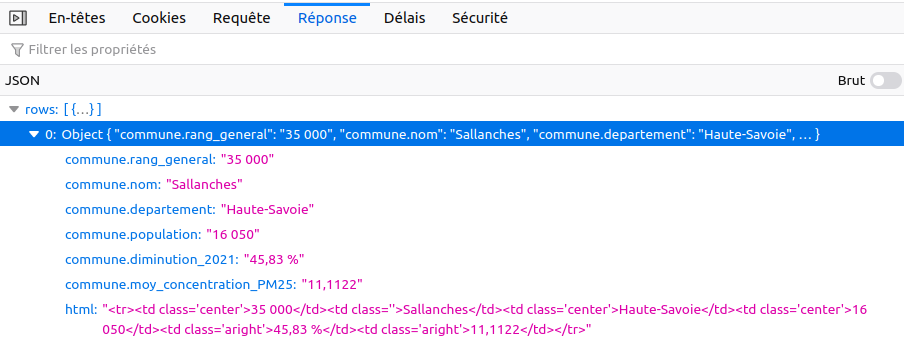
Là aussi c’est relativement parlant. On retrouve les données qui apparaissent dans le tableau du site internet du Point. Le champ html ne nous intéressera pas, mais on voit qu’il correspond au code html qui sera inséré dans la page tel quel par le code javascript.
Ensuite ? On teste depuis un environnement externe la même requête pour voir si ça marche ! Mais comment reproduire la même requête avec tous les headers et tout le tralala ? La réponse ci-dessous :
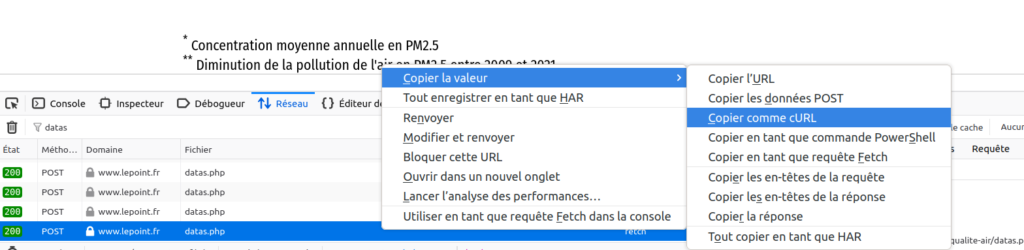
Un clic droit sur notre requête Ajax et on peut la copier en transcription cURL, super pratique ! Ensuite ouvrez votre terminal favori et/ou un éditeur texte et collez là dedans. Vous vous retrouvez avec une montagne d’informations. On va la simplifier au maximum pour ne garder que l’essentiel :
curl 'https://www.lepoint.fr/classements/qualite-air/datas.php' -X POST --data-raw '{"classement":"index","term":"Sallanches","type":"commune.nom"}'Langage du code : JavaScript (javascript)Ci-dessus la requête qu’on va tester dans notre terminal. On retrouve la méthode POST et le json payload comme vu précédemment. L’instant de vérité est proche car on a viré tous les headers / cookies potentiels… si ça fonctionne depuis notre terminal, ça fonctionnera partout sans restriction !

Et bim 😀 On a exécuté le cURL depuis notre terminal et on retrouve la même réponse que dans notre navigateur. Il n’y a donc aucune protection sur l’URL d’accès aux données du Point, ça va simplifier la suite. Si jamais l’URL avait été protégée il aurait fallu enquêter un peu plus pour joindre à cette requête un header d’autorisation ou quelque chose comme cela.
Première partie : faite. Dernier détail à noter sur le site du Point :
Le nom des communes correspond aux noms officiels des communes au 1er janvier 2017 (INSEE).
https://www.lepoint.fr/classements/qualite-air/
2/ Récupération des données sur les communes françaises
Vu qu’on cherche à reproduire la même requête que ci-dessus mais sur l’ensemble des communes de Haute-Savoie, il nous faut un référentiel pour obtenir cette liste. Le site du Point nous donne la réponse, ils utilisent la base INSEE des noms des communes en 2017. Il nous faut la même.
2.1/ Fichier Insee des communes françaises
Une rapide recherche Google et on tombe sur la page de L’Insee : https://www.insee.fr/fr/information/2666684#titre-bloc-7
L’Insee nous fourni 2 fichiers : un txt et un dbase. J’étais parti sur le txt pour commencer mais j’ai eu pas mal de soucis d’encodage, je ne sais pas si c’est lié au fait que je suis sur Linux mais ça ne marchait pas top (j’ai pas trop poussé les recherches). J’ai donc téléchargé le fichier .dbase pour l’exploiter dans LibreOffice Calc (équivalent d’Excel).
Il manque des informations dans ce fichier donc on utilisera un deuxième fichier pour joindre les deux et avoir des données sur les codes postaux et coordonnées GPS. En attendant, il faut choisir le bon encodage au moment de l’importer dans LibreOffice :
Et voici un aperçu des données ci-dessous. Les colonnes K et L correspondent aux noms des communes pour requêter l’API du site du Point. La colonne E correspond au code commune, elle nous servira pour faire la jointure avec un autre fichier référentiel.
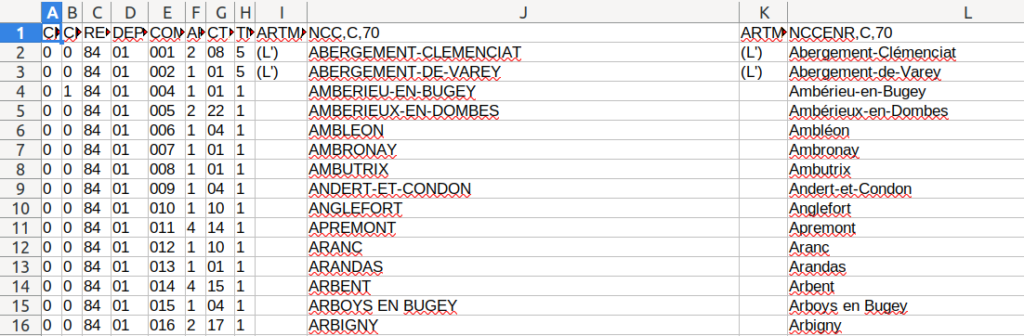
Ce fichier contient toutes les communes françaises, on lui fait faire une cure d’amaigrissement en filtrant uniquement sur le département 74.
On copie colle ensuite dans un nouveau fichier la sélection sur la Haute Savoie. Voici le résultat ci-dessous, 281 communes gardées (sur 35 000 au total) avec les entêtes en 1ere ligne. On l’enregistre sous le nom « liste_communes_haute_savoie.ods ».
2.2/ Fichier La Poste avec codes postaux et données GPS
Ce fichier de l’Insee étant plutôt incomplet, j’ai trouvé une source complémentaire à cette adresse : https://www.data.gouv.fr/fr/datasets/communes-de-france-base-des-codes-postaux/
Il ne s’agit pas de la liste des communes au 1er janvier 2017 donc on utilisera le fichier de l’Insee en référence et on fera un « left join » avec ce fichier secondaire qui contient le code postal et les coordonnées GPS de chaque commune.
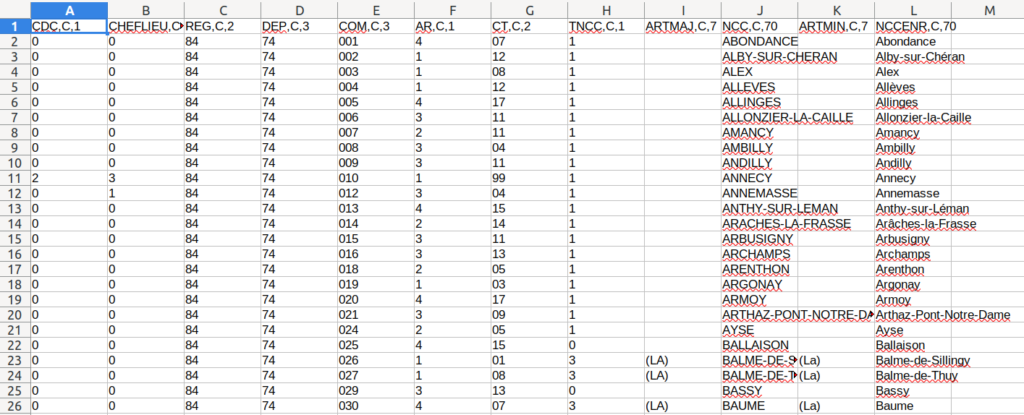
On importe le fichier des communes avec liste des codes postaux et données GPS qui s’appelle « communes-departement-region.csv » dans LibreOffice Calc :
Même principe que sur le premier fichier : on filtre sur la Haute-Savoie. Ici 331 lignes car il y a des doublons pour chaque commune (un peu plus de détail au niveau des anciens lieu-dit que le fichier de l’Insee).

Après ça, on copie / colle les données filtrées dans un nouveau fichier qu’on appelle « correspondance_gps_code_postal.ods ».
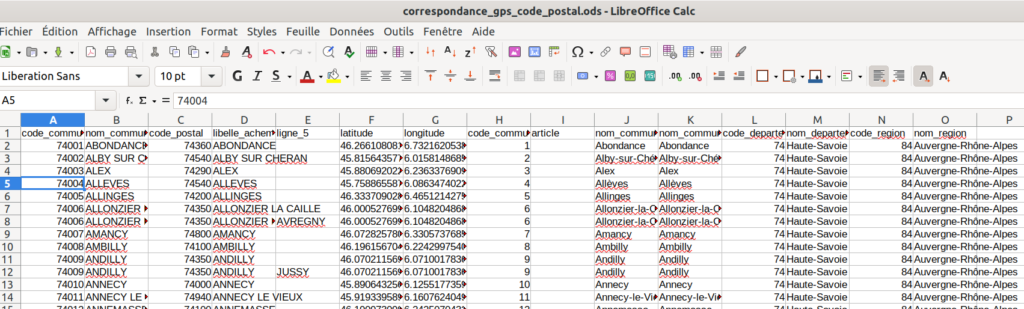
On va supprimer les lignes en doublon car elles ne nous sont pas utiles, c’est uniquement la colonne E qui diffère. On commence par enlever cette colonne. Ensuite on fait un filtre spécial :
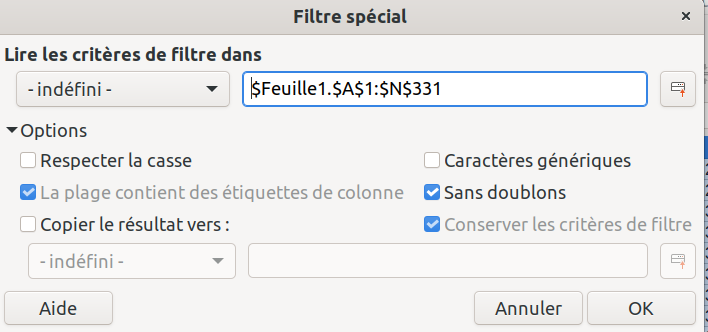
On sélectionne toutes nos données et on clique sur « sans doublons ». Le résultat final est de 293 lignes, soit un peu plus que notre fichier de référence, ce qui est très bien, car ça veut dire que notre fichier source pourra, a priori, conserver toutes ses lignes vu qu’on aura un « match » pour toutes les communes.
2.3/ Fusion des 2 fichiers
C’est l’heure de rapprocher les 2 fichiers en utilisant le fichier Insee comme référence. Pour faire la jointure (une RECHERCHEV dans le langage Excel / LibreOffice) on pourrait utiliser le nom de commune mais c’est toujours un peu plus propre d’utiliser des nombres. Pour cela on a le code commune INSEE présent dans les 2 fichiers.
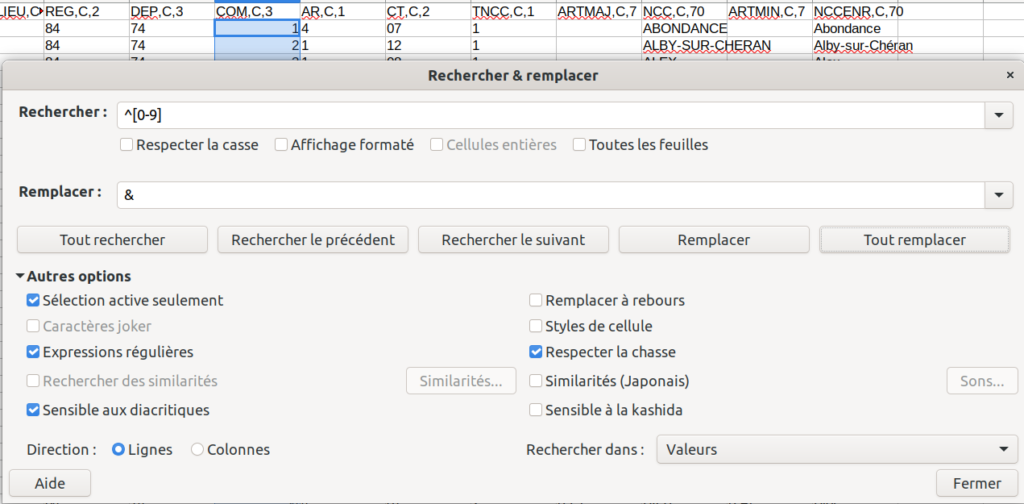
Malheureusement, le fichier Insee pour le champ « code commune » n’est pas encodé pareil que le fichier de correspondance. On doit donc convertir le code commune qui est encodé sur 3 caractères, de type 001. Pour cela une étape un peu compliquée décrite ici https://help.libreoffice.org/latest/ro/text/scalc/guide/integer_leading_zero.html?&DbPAR=SHARED&System=UNIX .
On converti la colonne en format nombre puis on applique une expression régulière pour rechercher et remplacer. On va passer de 001 à 1 grâce à la formule ci-dessous (qui va chercher que notre chaine de caractère commence par un nombre de 0 à 9).
Avant de faire le RECHERCHEV on doit aussi passer la colonne code_commune en première position du fichier de correspondance. Cette opération est nécessaire pour faire fonctionner le RECHERCHEV qui ira chercher une valeur (code commune du fichier de l’Insee) dans une plage de données en cherchant la correspondance sur cette première colonne.
Le fichier de correspondance ci-dessous avec la colonne code_commune déplacée en première position.
Puis on applique un RECHERCHEV pour faire la correspondance sur le code commune. Le but est d’afficher tous les champs du fichier « correspondance » à la suite de chaque commune de référence (en gras et en bleu ci-dessous).
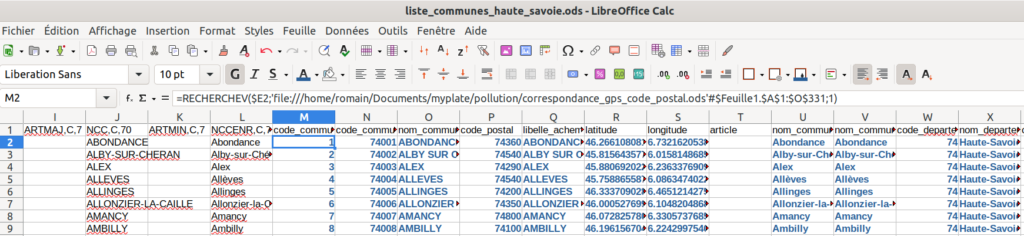
Une fois la RECHERCHEV faite, on sélectionne toutes les valeurs (en bleu donc) issues du 2ème fichier et on fait un copier / coller en valeur pour supprimer les références au 2eme fichier et ainsi gagner en performance (ça va délier les 2 fichiers en somme). Le fichier de correspondance n’est plus nécessaire à ce stade.
Il n’est plus utile mais on va garder uniquement ses colonnes :p On supprime toutes les colonnes initiales de A à L, soit l’entièreté du fichier de l’Insee car ses champs ne sont pas très pertinents et le fichier de correspondance a tout ce qu’il faut.
PS: A postériori ce n’était pas parfait comme technique car il y avait un écart sur le nom d’une commune entre les 2 fichiers. C’est écrit « Sévrier » dans le fichier de l’Insee et « Sevrier » dans le fichier de correspondance. Il faut donc bien avoir « Sévrier » pour que la requête avec l’API du Point fonctionne.
Pour résumé : Toutes ces étapes pour au final ne garder que le deuxième fichier mais minoré des doublons et des communes non listées dans le fichier de 2017. Ci-dessous un aperçu du fichier final qui nous servira pour faire les requêtes dans Symfony :
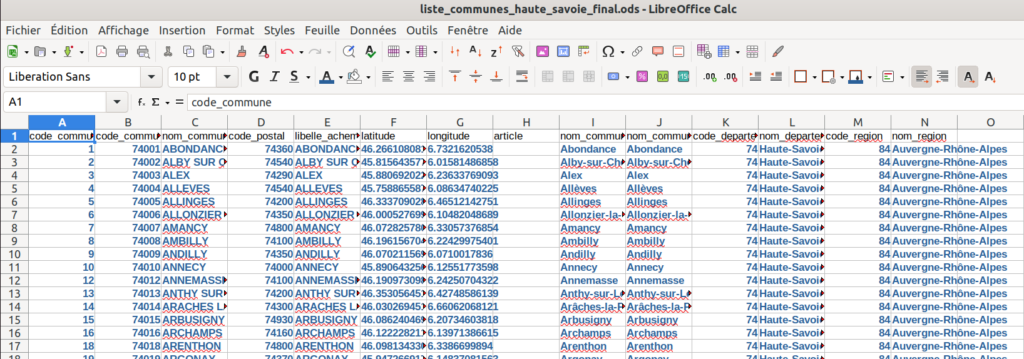
Ensuite on l’exporte au format CSV. On spécifie bien en UTF-8 pour l’export.
Voici un aperçu du fichier CSV qu’on va lire dans Symfony, les accents sont bien là. Le nom est « liste_communes_haute_savoie_final.csv ».

Hourra ! Nous y voilà enfin. On a notre CSV avec la liste de toutes les communes de Haute-Savoie. La suite ça se passe avec Symfony ci-dessous.
3/ Symfony pour faire les requêtes et récupérer les données de pollution
On revient aux choses sympa avec Symfony (c’est plus cool que de retravailler des fichiers Excel). On va faire très simple pour cette partie :
- Une entité Doctrine pour stocker nos villes en base de données
- Un Controller avec 2 méthodes (pour charger le CSV et récupérer les données de pollution)
3.1/ L’entité HauteSavoie pour stocker nos villes
Ci-dessous un extrait de notre entité Doctrine qu’on a simplement appelé « HauteSavoie ». On défini quelques propriétés qui vont nous servir à stocker les informations sur chaque ville : nom, population, pollution aux PM2.5, latitude, longitude,…
<?php
namespace App\Entity;
use App\Repository\HauteSavoieRepository;
use Doctrine\ORM\Mapping as ORM;
#[ORM\Entity(repositoryClass: HauteSavoieRepository::class)]
class HauteSavoie
{
#[ORM\Id]
#[ORM\GeneratedValue]
#[ORM\Column]
private ?int $id = null;
#[ORM\Column(length: 255)]
private ?string $cityName = null;
#[ORM\Column(length: 5)]
private ?string $zipCode = null;
#[ORM\Column]
private ?float $lat = null;
#[ORM\Column]
private ?float $lng = null;
#[ORM\Column]
private ?int $departementId = null;
#[ORM\Column(length: 255)]
private ?string $departementName = null;
#[ORM\Column(nullable: true)]
private ?int $population = null;
#[ORM\Column(nullable: true)]
private ?int $rank = null;
#[ORM\Column(nullable: true)]
private ?float $pm25 = null;
public function getId(): ?int
{
return $this->id;
}
// la suite des getters et settersLangage du code : PHP (php)Votre application Symfony peut-être n’importe quelle application existante tournant en local ou en production. Ici j’ai utilisé une application un peu fourre-tout qui me sert à faire des tests et demonstrations. On est aussi sur « quick and dirty », c’est à dire que les « Best practices » ne sont pas au cœur du sujet, l’essentiel c’était de faire un truc qui fonctionne sans se prendre la tête.
Note technique : ma stack Symfony tourne sur Docker en local, j’utilise PostgreSQL pour la base de données, Caddy pour le serveur Web. N’importe quelle application Symfony peut faire l’affaire du moment que HttpClient est installé. J’utilise Symfony mais ça fonctionne aussi avec n’importe quel autre langage de programmation et/ou framework.
3.2/ La méthode pour charger le CSV
Trêve de blabla, un extrait du Controller pour charger le fichier CSV de données :
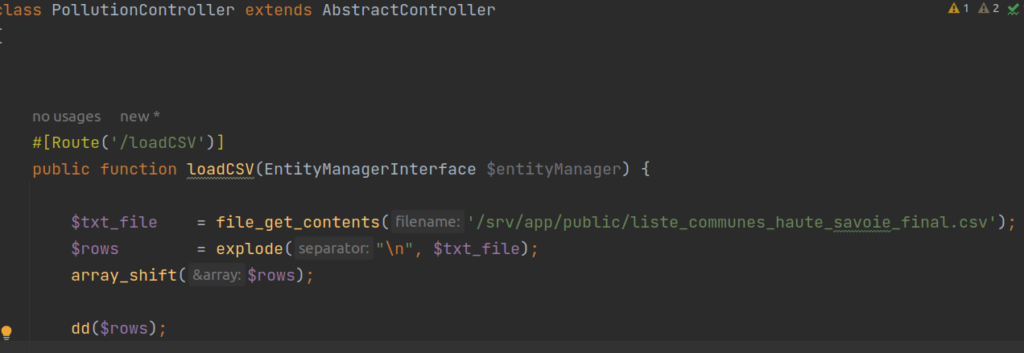
Là c’est très simple. On défini un Controller, accessible à l’URL /loadCSV, qui va lire et mettre le contenu de notre CSV dans une variable $txt_file. On pourrait aussi utiliser la fonction fopen() et « streamer » le contenu mais notre fichier est léger ici. Le CSV a été au préalable mis dans le dossier public de l’application Symfony. On ne s’intéresse pas du tout à d’éventuelles mesures de sécurité pour protéger l’accès à ce fichier car c’est uniquement une appli qui tourne en local sur mon pc.
Ensuite on « explode » cette variable pour avoir un array (tableau) qui contiendra un array par ligne (ville). Avec array_shift on supprime la ligne d’entête. Et on fait un dd (dump & die) pour afficher le contenu du CSV :

On le voit ci-dessus, on a bien un array pour chaque ville, les accents ont bien été conservés. Tout semble ok.
Ci-dessous l’intégralité de la méthode loadCSV :
<?php
namespace App\Controller;
use App\Entity\HauteSavoie;
use App\Repository\HauteSavoieRepository;
use Doctrine\ORM\EntityManagerInterface;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\Routing\Annotation\Route;
use Symfony\Contracts\HttpClient\HttpClientInterface;
class PollutionController extends AbstractController
{
#[Route('/loadCSV')]
public function loadCSV(EntityManagerInterface $entityManager)
{
//on lit le fichier CSV et on met le contenu dans une variable
$txt_file = file_get_contents('/srv/app/public/liste_communes_haute_savoie_final.csv');
// on split par ligne
$rows = explode("\n", $txt_file);
//on supprime la ligne avec les en-têtes
array_shift($rows);
//on parcourt chaque ligne (ville) du fichier
foreach ($rows as $data) {
//on vérifie que notre ligne n'est pas nulle ou vide
if ($data !== '' && $data !== null) {
//on split chaque ligne (ville) pour extraire les données
$row_data = explode(",", $data);
//création d'une nouvelle instance de HauteSavoie
$city = new HauteSavoie();
//on récupère la dixième colonne (ça commence à l'index 0) pour le nom de ville
$city->setCityName($row_data[9]);
//même principe pour tous les autres champs
$city->setZipCode($row_data[3]);
$city->setLat($row_data[5]);
$city->setLng($row_data[6]);
$city->setDepartementName($row_data[11]);
$city->setDepartementId($row_data[10]);
//On persiste notre objet HauteSavoie
$entityManager->persist($city);
}
}
//on flush toutes les opérations en base
$entityManager->flush();
//dump & die pour arrêter le script mais on devrait plutôt renvoyer une belle réponse
dd();
}Langage du code : PHP (php)Le principe est simple. On split notre fichier CSV pour extraire les informations et ensuite créer une nouvelle entité pour chaque ville. Le résultat donne 281 lignes dans notre table « haute_savoie ». Ce Controller n’est à exécuter qu’une seule fois car sinon on va insérer les mêmes lignes en doublon à chaque nouvel appel (on pourrait s’en prémunir en rajoutant une contrainte de UniqueEntity).
3.3/ La méthode pour récupérer les données de pollution
Ci-dessous la méthode getData qui est le cœur du sujet. C’est dans cette méthode qu’on va lire les données de notre table « haute_savoie » et venir faire, pour chaque ville, une requête vers l’API du Point pour récupérer les données de pollution.
#[Route('/getData')]
public function getData(HttpClientInterface $httpClient, HauteSavoieRepository $hauteSavoieRepository, EntityManagerInterface $entityManager)
{
//on va chercher tous nos enregistrements en base de données
$cities = $hauteSavoieRepository->findAll();
//on boucle sur chaque ville
foreach ($cities as $city) {
//si on n'a pas déjà l'information sur la pollution aux PM2.5
if ($city->getPm25() === null) {
//le cœur du sujet : la requête vers l'api du Point pour récupérer les données de pollution
$response = $httpClient->request('POST', 'https://www.lepoint.fr/classements/qualite-air/datas.php', [
'json' => [
'classement' => 'index',
'term' => $city->getCityName(),
'type' => 'commune.nom'
]
]);
//si la réponse est OK et qu'on a des lignes
if ($response->getStatusCode() === 200 && array_key_exists('rows', $response->toArray())) {
//on stock les résultats dans la variable results
$results = $response->toArray()['rows'];
//si notre array de results n'est effectivement pas vide
if(!empty($results)) {
//on ne garde que les résultats pour les villes de Haute-Savoie
//Ex : pour Passy qui est une commune présente dans plusieurs départements
//On ne doit garder le résultat que pour la ville de Passy en Haute-Savoie
$goodCity = array_values(array_filter($results, function ($value) {
return 'Haute-Savoie' === $value['commune.departement'];
}))[0];
//Si le résultat de la ville en question a bien des données de pollution
if (array_key_exists('commune.moy_concentration_PM25', $goodCity)) {
//on reformate et on affecte le resultat à la variable rank pour le rang général
$rank = (int)str_replace(' ', '', $goodCity['commune.rang_general']);
//on reformate et on affecte le resultat à la variable pop pour la population de la commune
$pop = (int)str_replace(' ', '', $goodCity['commune.population']);
//on reformate et on affecte le resultat à la variable pm25 pour la concentration en particules PM2.5
$pm25 = (float)str_replace(',', '.', $goodCity['commune.moy_concentration_PM25']);
//on update notre entité avec les nouvelles valeurs
$city->setRank($rank);
$city->setPopulation($pop);
$city->setPm25($pm25);
}
}
}
}
}
//on flush les résultats en base
$entityManager->flush();
//on dump & die mais on devrait renvoyer une belle réponse
dd();
}
Langage du code : PHP (php)J’ai commenté chaque instruction pour y voir plus clair.
Sur les lignes de 14 à 20 on utilise le composant httpClient pour venir faire une requête (en cURL si c’est installé) vers l’API du Point. On fait une requête de type POST avec un json payload qui correspond exactement à la même requête que faisait notre navigateur (ou notre script cURL) au début de l’article. Ce script va donc exécuter 281 requêtes en quelques secondes vers le site internet du Point… vous auriez pu faire la même chose à la main mais ça aurait pris quelques heures 😉
Ensuite on exploite les résultats de cette requête en faisant juste attention à bien traiter les villes qui sont présentes dans plusieurs départements, c’est ce qu’on fait sur les lignes de 31 à 36. J’enchaine les fonctions array_filter et array_values pour extraire les bonnes données relatives à la commune de Haute-Savoie si jamais on a d’autres départements dans les résultats.
Exemple des résultats quand on fait une requête avec le terme « Passy » :
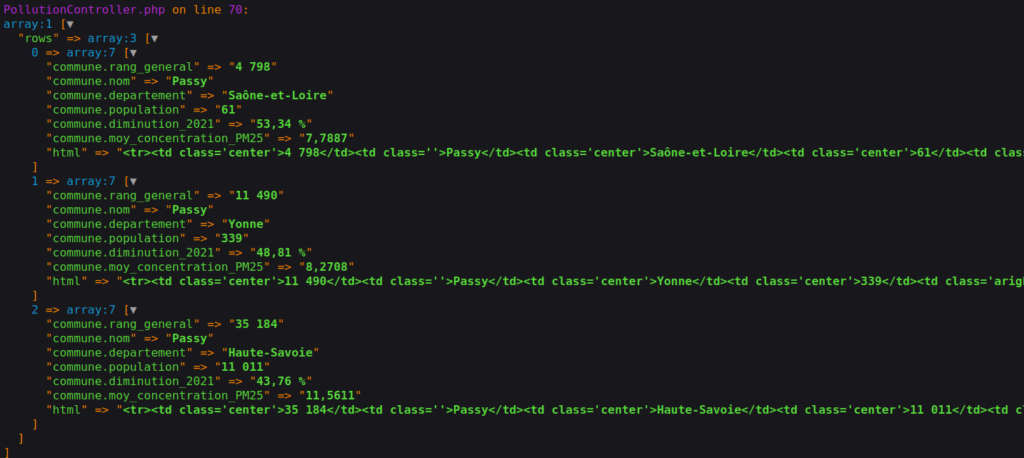
Et c’est fini ! Champagne 🍾 Vous pouvez célébrer en allant voir les données de votre table SQL « haute_savoie » :
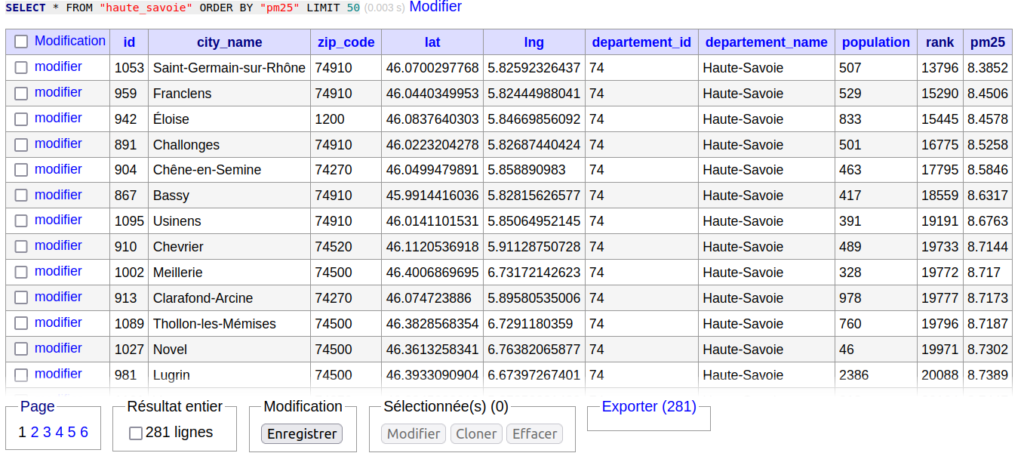
Ci-dessus nos résultats triés par concentration en particules fines pm2.5. On apprend donc que la ville la moins polluée de Haute-Savoie est Saint-Germain-sur-Rhône avec une concentration moyenne annuelle de 8,38 µg/m3, elle se situe à la 13 796ème place française. A contrario, Domancy est la commune la plus polluée de Haute-Savoie avec une concentration qui dépasse les 12 🙁 Elle se classe 35 242ème sur 35 279, une vraie cata !
Ce tableau s’est bien mais on peut faire mieux. Avoir une belle carte qui mettrait les zones de Haute-Savoie en évidence ça serait mieux non ? C’est dans la dernière partie ci-dessous.
4/ Création d’une carte sur la pollution en Haute-Savoie aux PM2.5
Je vais utiliser le logiciel Tableau Software pour créer nos data visualisations (nos cartes de pollution quoi). C’est payant (70€/mois) mais il y a 14 jours gratuits au début. Pareil, je connais bien Tableau donc j’utilise ça mais il y a plein d’autres façons de faire des cartes. On aurait pu la faire en utilisant Mapbox directement avec Javascript (et c’est gratuit).
4.1/ Insertion et préparation des données dans Tableau
Avant d’ouvrir Tableau, on exporte les données de notre table SQL au format CSV. Vu la taille du fichier, ça sera le plus pratique, pas besoin ici de se connecter à une source de données dans le cloud ou truc dans le genre 🙂
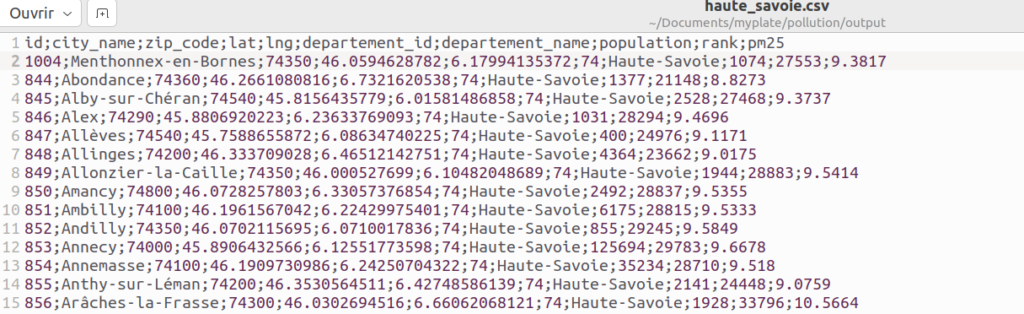
La première étape est d’importer notre CSV dans Tableau en tant que source de données. Par défaut Tableau va inférer les types de colonnes en fonction des valeurs qu’elles contiennent. Il est plutôt smart mais quelques petites modifications s’imposent. Le champ « lat » a bien été catégorisé par Tableau en tant que rôle géographique de latitude. Pour le champ « lng » il n’a rien trouvé donc on va lui dire que c’est un rôle géographique de longitude :
Même chose ci-dessous avec le nom du département, on peut indiquer à Tableau que c’est un « comté 🧀 ». En langage Tableau, un comté équivaut au niveau administratif d’un département.
Maintenant que notre source de données est prête on peut ouvrir un classeur pour créer notre carte !
Même si nos données contiennent le code postal et le nom de la commune, je vais me contenter d’utiliser uniquement la latitude et longitude. On peut créer nos cartes en disant à Tableau d’utiliser le nom de la commune et c’est lui même qui va se charger de définir les contours et données GPS par rapport à sa base de connaissance. Même principe pour le code postal. Cette technique est très bien mais il y a des erreurs de catégorisation puisque Tableau infère des données GPS à partir de noms de communes ou de numéro de code postal et il ne devine pas tout correctement.
Une fois dans notre classeur, on va transformer le rôle des variables « lat » et « lng » en dimension. Un clic droit sur la valeur et on sélectionne « Convertir en dimension » :
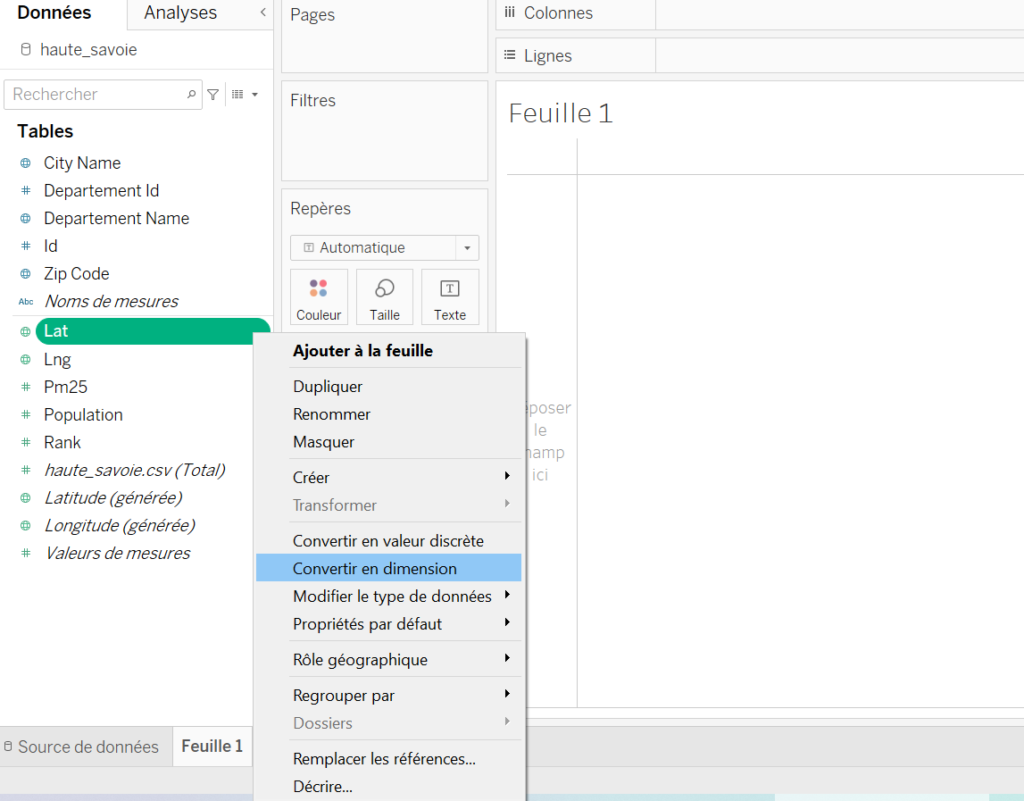
Quand c’est ok, on glisse la valeur « Lng » sur l’étagère « Colonnes » et la valeur « Lat » sur l’étagère « Lignes ». Tableau sait que c’est des données géographiques et affiche automatiquement une carte :
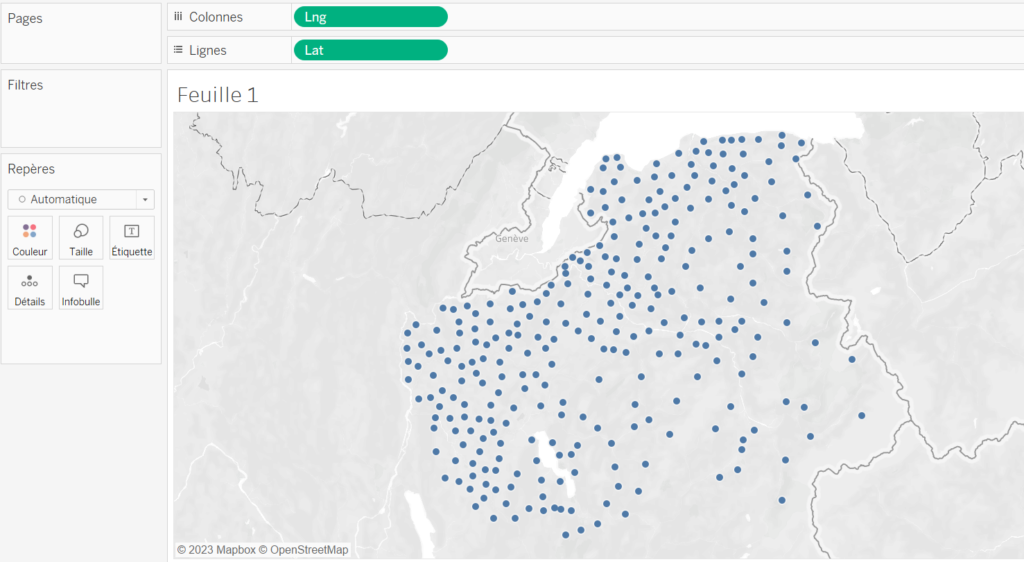
On reconnait les contours de la Haute-Savoie, nos données GPS étaient donc fiables.
Si on faisait le test avec le code postal et / ou nom de commune, on aurait eu des petits points un peu partout en France ! Là c’est plus simple, ça fonctionne direct. Le seul inconvénient c’est qu’on sera limité à l’affichage de points et on ne pourra pas faire de zones. On aurait pu pousser plus loin et venir croiser nos données avec les contours des communes (données disponibles en open source) mais ça rajouterait un peu plus de travail.
4.2/ Personnalisation de la carte
Maintenant qu’on a une carte de base on va l’embellir pour la rendre plus lisible et pertinente. Il y a 15 000 façons de la personnaliser. Je montre ci-dessous quelques façons de faire.
On commence par faire varier la couleur de nos points en fonction de la concentration en particules fines. Il faut faire glisser la valeur « Pm25 » sur la zone « Couleur » et le tour est joué.
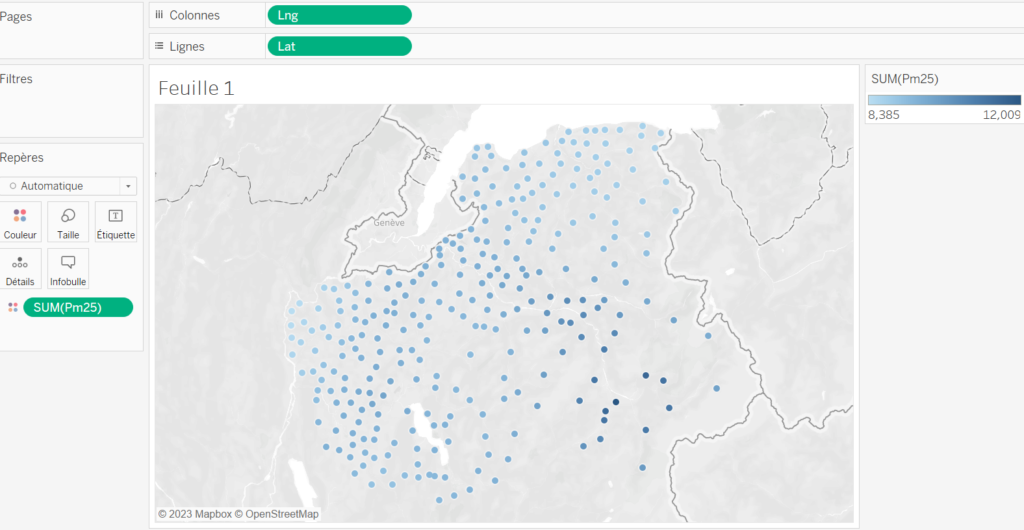
Pour voir où on se situe, on peut ajouter quelques noms de villes. On fait glisser notre champ « City Name » sur la zone « Etiquette ». Par défaut il affiche quelques noms de communes. On peut affiner tout ça ensuite en modifiant les options d’affichage.
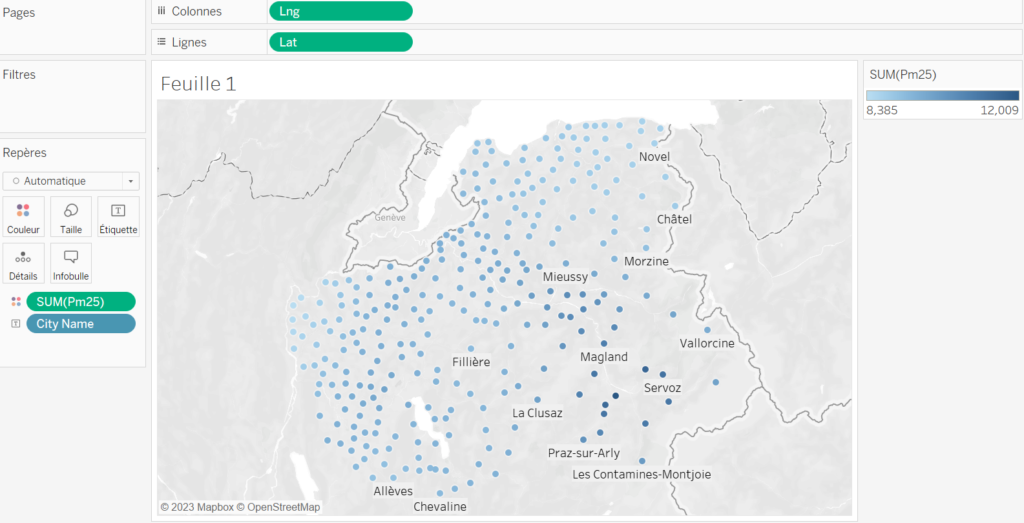
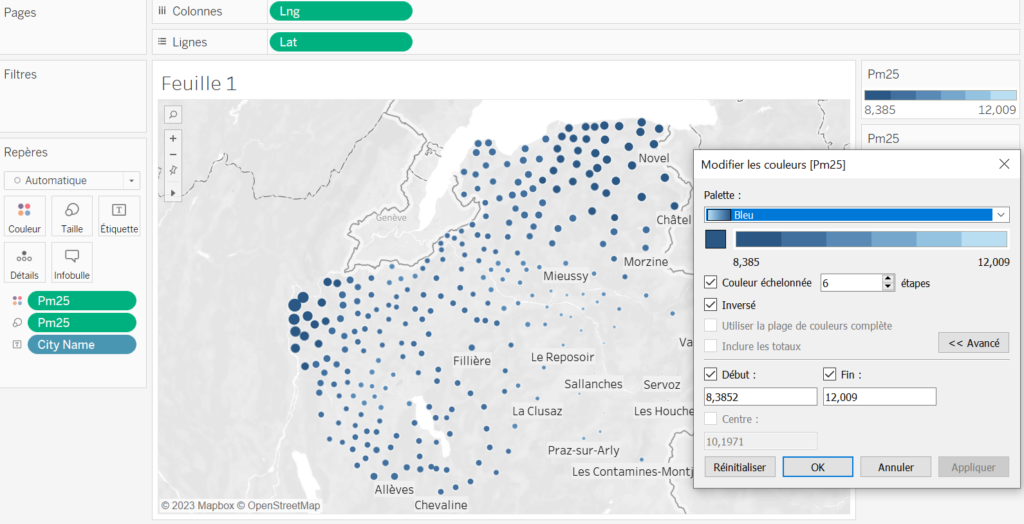
En parlant d’options, et si on modifiait les couleurs ? On peut définir des plages, inverser les couleurs, choisir la palette,…
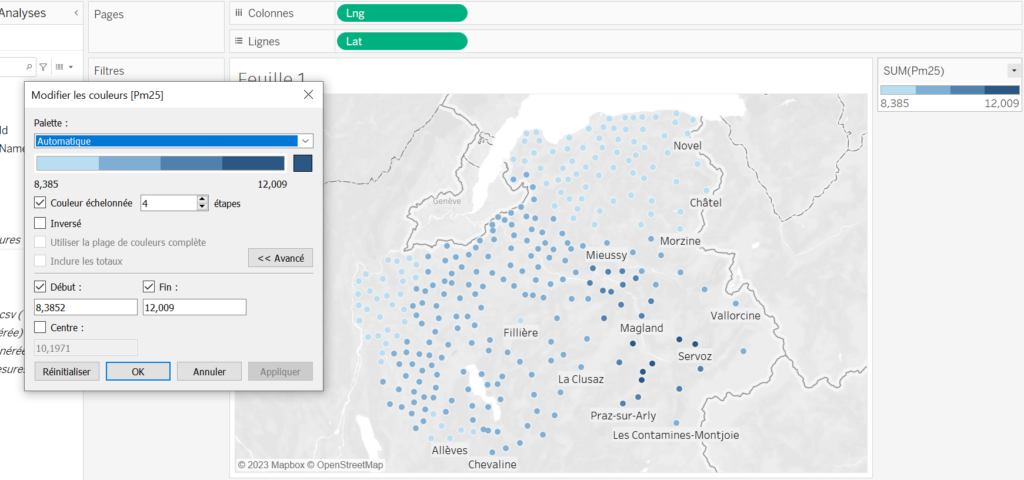
Par défaut, Tableau a inséré notre champ « Pm25 » en faisant une somme sur ses valeurs par point géographique. Vu qu’on a qu’une seule valeur, ça ne change rien, mais on peut lui dire de faire autrement en faisant un clic droit :
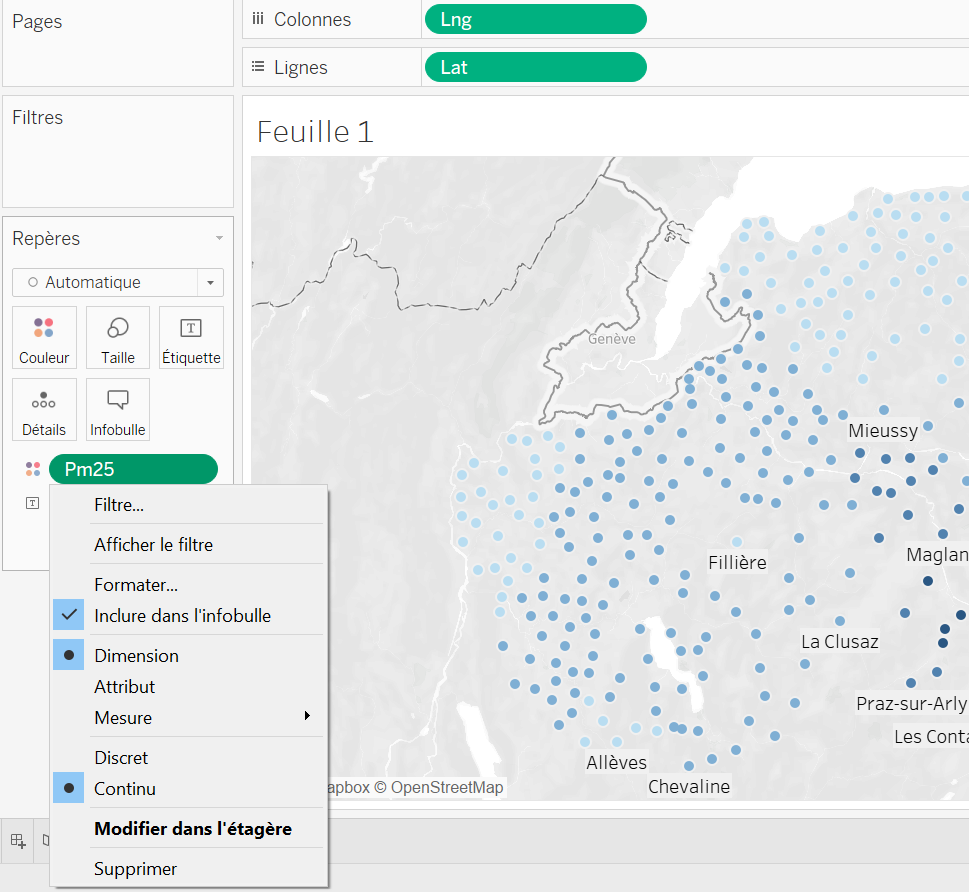
Pour différencier encore mieux les zones, on va aussi faire varier la taille des points en fonction du taux de particules fines. Même concept que pour la couleur.
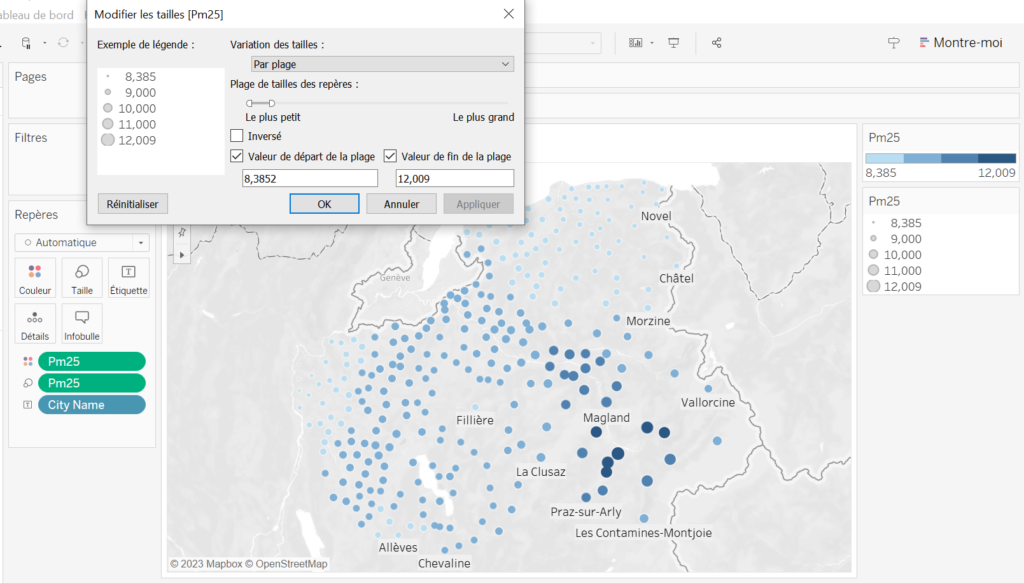
Ci-dessous on inverse les couleurs et tailles pour faire ressortir les zones les moins polluées.
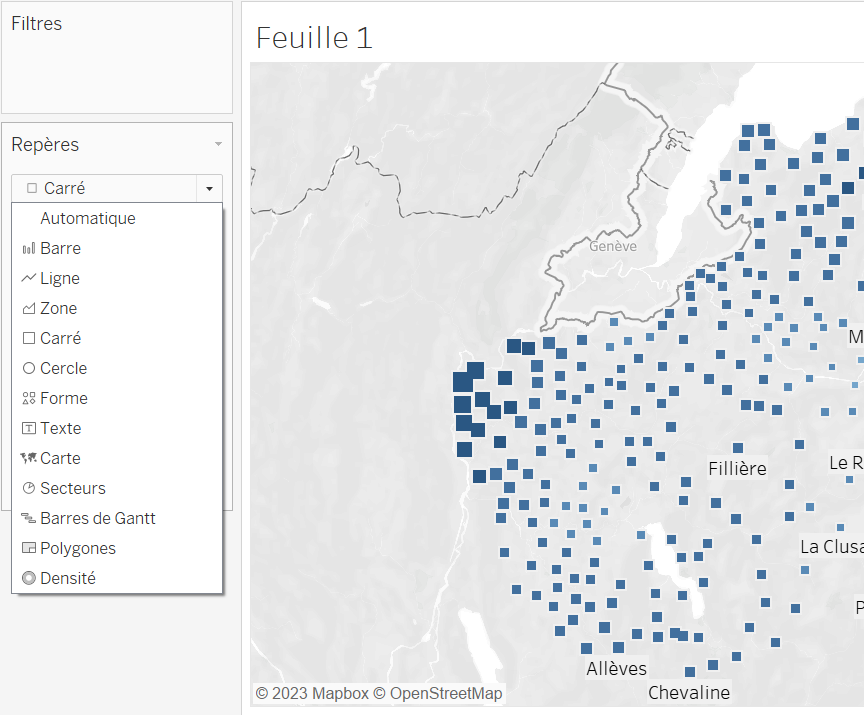
On peut aussi remplacer nos points par des carrés :
Autre étape de personnalisation : changer le fond de carte !
Pas mal d’options mais on va choisir « extérieur » pour faire ressortir le côté vallée / montagnes.
Le fond de carte devient un peut trop voyant alors on choisi de modifier son opacité pour qu’il ressorte un peu moins :
Et voilà on a une carte qui devient vraiment sympa. On pourrait encore modifier / ajouter plein de choses mais avec les 2 cartes ci-dessous on y voit déjà plus clair sur la répartition de la pollution de l’air en Haute-Savoie.
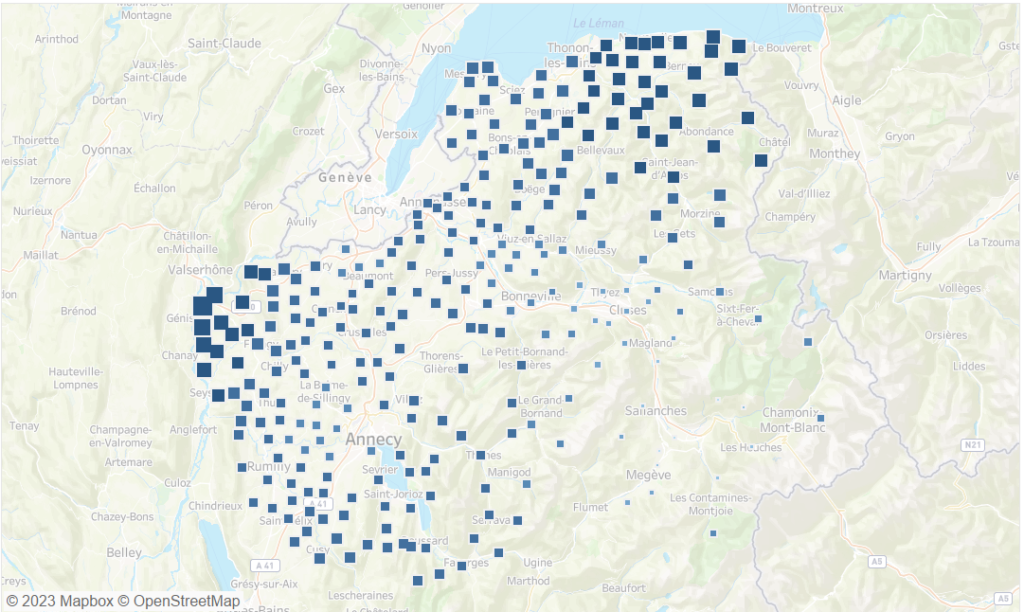
Ci-dessous, plus c’est bleu foncé et gros, moins c’est pollué.
La version opposée ci-dessous. Plus c’est gros et bleu foncé, plus c’est pollué.
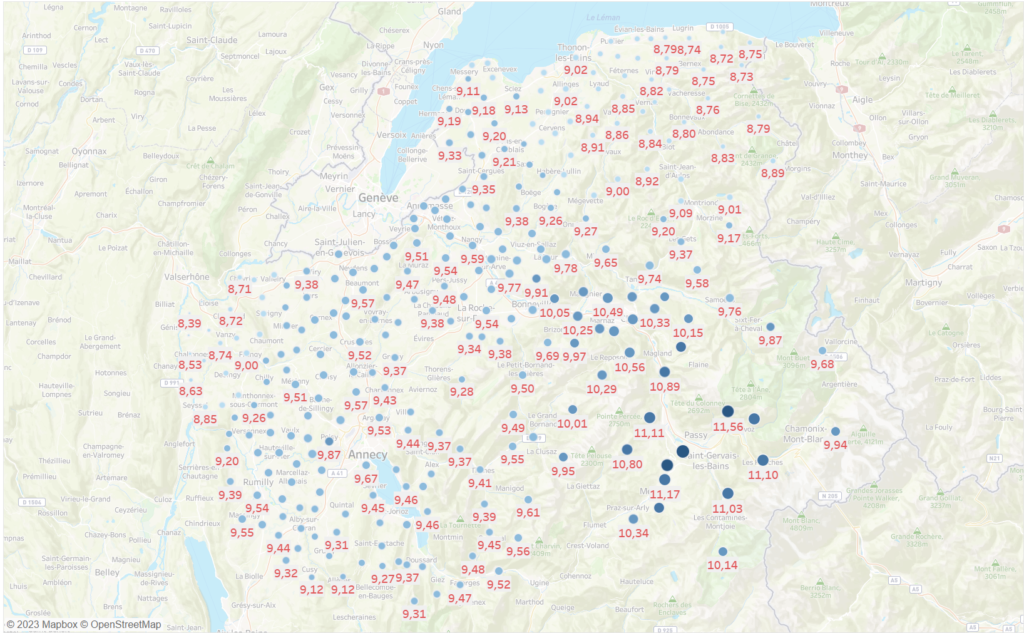
5/ Conclusion
Merci au magazine Le Point d’avoir sorti ces chiffres. Ils ne sont vraiment pas bon pour la Haute-Savoie et en particulier pour la vallée de l’Arve.
Quant à moi, j’ai trouvé super intéressant d’utiliser ce jeu de données pour exploiter 2 facettes de mes compétences : Développement web et Data analyse. C’était le use case parfait comme on dit !